It was a fricking hard day today, 20/5/26. Umm, where do I start? I have a genuine curiosity towards automating stuff. (I'm damn lazy when it comes to writing and documenting stuff). From the beginning of my Internet journey around 1998 on a modem, I have been fascinated by websites, blogs, and interesting content.
Later I developed this curiosity into something that aligned well with my fascination with automating stuff. I had dozens of domains. I heavily used WordPress for an easy kickstart to those domains and didn't bother myself with web design because there were thousands of awesome, free-to-use WordPress templates. I used unique templates for my domains. WordPress was very ahead of its time. It had plugin support (for PHP plugins). I literally fell in to love with one specific plugin. The plugin fetched rss/atom feeds from very popular tech blogs, all I had to do was write an article spinner at the end of that plugin to create my own "original" content. Yes, that upset many hard working bloggers and writers back in the day. To me, this was a very interesting experiment: how much I can get away without being caught or sandboxed by search engines. I did pretty good. I had google adsense set on the websites, as a newly graduated computer science student, I was earning $300-$500 for that time, 2007-2012. But with anything too good to be true my "easy money" (as in the movie Terminator) period ended. I got lots of dmca complaints, had sandboxed tens of times. Search engines got better and started ignoring those auto generated similar web content. This was like a cat and mouse game. It was awesome while it lasted.
Years later the ambition for automation is still strong as it was back then too. But the rules of the game changed. We now have more powerful tools called "LLMs" (language models). These little buggers are so frikking awesome at coding and doing ordinary routine work. With a big mistake, I thought these buggers are also good at generating "original" articles/contents. Oh, I couldn't have been more wrong.
These models (trained neural nets), actually pretty bad at creating original content. It costed me a couple hundred bucks to discover that I was very naive to put my trust on these buggers for human-like text generation and originality.
Where do I begin? I have a couple of domains, that I had set up some pipeline in the backend for LLM based content generation. At first, everything looked "okay", I was even impressed "Wow nice articles and passages". The more I looked the more it started to feel, "Oh, I think Im digging myself into a hole". Then I decided to follow the rabbit hole, for sake of learning new stuff. You can not learn new things without failing. Every failure taught me something very important. Especially in my profession Computer Science.
So I wasnt afraid to fail marvelously :D. The intro 101 to these text vomitting machines are em-dashes. They are like watermarks. However they are really easy to get rid of and are not even the tip of the tip of the iceberg. I was able to clean them with simple regex or just plain old replace char.
I researched deeper, and then came the vocabulary markers. "Delve", "Tapestry", "Myriad", "Plethora", "in the realm of". My hands are still shaking from fear that this long-ass post will came out as %100 AI-Generated on LLM checkers. Oh yes, Pangram is the big boss, GptZero and many others.
For those who wonder, yes there are these services checks texts against llm generation. Some of them are pretty easy to beat, some like Pangram there is no consistent winning strategy agains them which works %100 of the time. So? Basically, no automation.
Let's continue. There are dozens if not hundreds or if not thousands of "template phrases". Which these language models love to use them sprinkle them everywhere, the more you carefully look the more it becomes clearer. I am listing here a few types:
"X is one of those Y that Z".
"X is now a recognizable Y"
"an entire generation of X learned to Y"
Ohh and also the famous "in retrospect" and "looking back". You get the idea. If you can eliminate these mechanical looking structures, my sweet summer child, you can only walk so far.
It doesnt end here, let's march to "Structural patterns" or "Triadic Structures".
"X did A. X did B. X did C".
Let' me give a more concrete examle, look at the following sentence;
"The screen name was X. The away message was Y. The door slam was Z."
The bugger generated this for an old messaging app and many others along with this. The whole article about an old messaging app looked so mechanic and so artificial.
Believe me, I'm not a cheapskate, I have used frontier models like Opus 4.7, Gemini Pro and etc.. The harder I tried the harder I failed. With one weird thing also I have noticed was symmetric doublings, "he wanted email when he wanted email", this pattern was also ubiquitous.
I also used long ass .md files as directives, and I wanted the language model to write the articles from a very detailed description of a persona. I gave age, profession, hobbies and everything. Still failed, failed harder. After each new generation of article, post, I have used those llm detectors, and dug my self deeper :D.
I then noticed another structural repeating pattern, Rhetorical Scaffolds. Look at the examples below;
"looks like X but is actually Y" contrast inversion
"did not survive -year-" / "the broader X reckoning"
"the thesis that..."
These are very prominent finger prints that are existing for of almost every languange model. Are we finished ? No. Let's continue. There are very easy to spot closing-sentence structures. When these language models think it is time to finish the idea, concept, or a paragraph, they polish it with some template ending sentences like;
"that gap is now permanent"
"only one of them is yours"
"that whole texture is gone"
"the X that produced Y is gone"
"that was the whole point"
When you start looking for these, they are really easy to notice, and of course you can train models to spot these finger prints. We are all now familiar with the concept of Dead-Internet. It is a reality now. Every new stuff that is produced, or every interaction or reactions on the internet are highly likely synthetic, not a genuine human product. Mostly bots, language models, image models, video models and audio models. Nowadays it is very hard to come by with genuine human creativity. So we can easily spot if a content is human-made or generated. Because we have enough generated content, so that training a model on these generated data is very preliminary. In fact, all frontier models are already trained on existing human text. Humanity's all knowledge base. So in each iteration they try to improve the model with structural changes, since there is no new data. New human text/knowledge/creation is so rare. Anyways let's continue.
Sentences have rhytms when they are generated by these languange models. They are very predictable. Mean word count 12, with a standard deviation ~3. Also the comma placements are very on point, there are no fragments and every paragraph start has its own topic sentence first. Pangram, GPTzero like detector all know about these distributional fingerprints model by model, so they can even predict the used model. If you think you are safe by randomly dropping apostrophes or replacing common words like "because" with "becuz" or similar word spinning, you are very wrong. They are also trained on these humanizer tricks, their dataset has these intentional noise patterns. So what can you do? Well, researchers are trying different attacking techniques for these detectors. One of them is pretty good at confusing Pangram and GPTZero. It's called adversarial paraphrasing. Basically altering the words, and structures but keeping the meaning unchanged. I tried using different models sequentially on the same text to come up with a morphed text but with the same meaning. I did pretty good too. However, it is still not enough on its own to trick these detectors.
So I decided to vibe code an attack pipeline to avoid these detectors. I have managed to put a complex series of text manipulations in this pipeline to win this battle. The results were very surprising. The attacks by themselves were not successful, however when applied together, they created a synergy to confuse these advance detectors. My long ass llm generated, posts/articles were sucessful at deceiving these. When I applied those attack vectors in small groups, the accuracy of those detectors started to drop significantly. Detectors were telling that 50% was AI-generated, then 40%, 30%, 7%, 3%, and finally 0%.
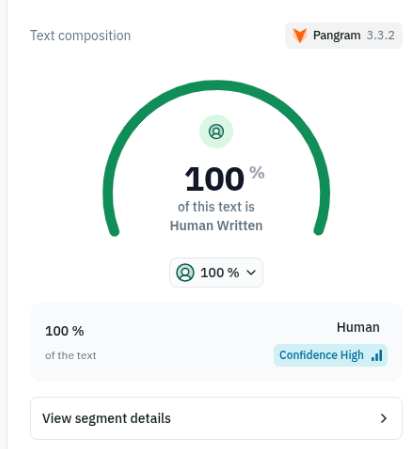
Pangram 100% Human Written, High Confidence. The total winning moment.
So my generated texts became 100% human-written with high confidence. It felt like a total winning moment. It didn't last very long :D. I was able consistently produce the same text with being able to fool these detectors 100%. However this was for one specific article. When I tried to scale this to a whole bunch of articles/posts, things went downhill. But results were still interesting, I can't give a clear picture, because I didn't have a paid subscription to test everything automatically via apis. But I was able to signup with different emails before I have been able to test 30-40 different articles/posts. Results were roughly 50-50. Half of the articles were labelled as 100% AI produced with High Confidence, and other half were labelled as 100% Human with High Confidence.
So in consequence, no matter how much I made the attack pipeline more complex didn't matter. Those detectors accumulate signals, in a large enough context the pipeline emitted enough signals for the text to be labelled as 100% AI. There is no in between. Below is the pipeline that I designed and wrote using Opus 4.7. So after getting myself out of the hole that I dug myselft into, I admitted defeat. Sometimes it best to know when to stop. Anyway, I can not look at the LLM generated text the same anymore. Maybe it is an essential skill for us to continue transferring information using our own sentences :D. Personally I am not against using them to show a more structured, mechanic block of text for information, but since it can be penalized for not being original, that is discouraging. Being original will be more and more important in the future. In world where people are becoming lazier and using these tools, it will be a distinguishing point, and it will be more important. I feel very lucky that daily usage of these LLMs came into my life after 40. I'm already satisfied with myself and was able to code software by hand throughout my career, I can benefit using them as code generators (never for text again). But if I was a young engineer or a fresh graduate, I would be very anxious about the future. I am all anxious for you my fellow friends, the future is very blur now, at least try to grasp the concepts and then maybe get the help from these language models. Never trust them when you yourself don't know the underlying concepts, LLMs are still failing to create original texts, I can't imagine using them for very complex problems. A fool with a tool is a more powerful fool.
Burak.
Beware the following chunk of text block is LLM Generated :D.
DETECTOR BYPASS PIPELINE - ORDER OF OPERATIONS
Input: AI-generated grave HTML body
Output: rewritten body that scores Human on Pangram
No LLM calls. Pure Python regex + heuristics.
1. PARSE
Split body into structural parts: h2 headers, p paragraphs, ul, blockquote.
2. FOR EACH PARAGRAPH:
2a. Check if inside a closing section.
Closing sections: "how it died", "what it left", "aftermath",
"the aesthetic", "the legacy", etc.
If yes AND this is the 2nd+ paragraph of that section: DROP.
(Essay reflection content; structurally AI, no rewrite helps.)
2b. Score AI risk, 0 to 5:
+1 if no first-person (i, me, my)
+1 if no second-person (you, your)
+1 if contains essay words (texture, moment, era, legacy, gone)
+1 if contains triadic parallel sentence structure
+2 if in a closing section
Threshold: risk >= 2 means "high risk".
3. TRANSFORMS, applied in order:
Layer A - text-level, always applied:
- Strip 50 AI-overused words (important, simply, particularly,
essentially, incredibly, "in many ways", "to some extent", ...)
- Casual contractions (going to -> gonna, want to -> wanna)
- Year shortcuts (2017 -> '17), 30% of years
- Active/passive flip ("X was bought by Y" -> "Y bought X"), 50%
- Date/number precision drop ("15 december 2017" -> "december 2017"),
40%
Layer B - high-risk paragraphs only:
- Drop "X is one of those Y that Z" essay template
- Inject one honest-distance opener at the start of the paragraph,
chosen by paragraph_index modulo opener list, no random.
(Avoids repeating the same opener twice in the grave.)
Split content into sentences.
Layer C - sentence drops, always applied:
- Drop essay-template sentences:
"X defined a moment for [country|era|generation]"
"X synonymous with Y"
"the iconic X was the Y"
"the X was your first Y"
- Drop generic-closer sentences:
"modern X are too Y"
"you cannot X because/by Y"
"there is no X anyone Y"
"the time that produced X is gone"
"is now a recognizable design genre"
"an entire generation learned to Y"
- Break "you knew when X. you knew when Y. you knew when Z."
triadic into a single comma-joined sentence with middle items
dropped.
Layer D - high-risk paragraphs only:
- Break "X was your A. Y was your B. Z was your C." parallel:
keep first and last, drop middle ones.
- Break generic 3-sentence parallel structures (same opening word,
same was/is verb pattern).
- Drop essay coda if the paragraph's final sentence matches:
"that whole X is gone"
"only X are yours"
"is none of those things"
"that gap is now permanent"
"has been revived in recent years as a Y"
Layer E - rhythm manipulation, always applied:
- Merge short adjacent sentences (<=12 words each) with comma,
85% probability per pair.
- Split long sentences (>16 words) at conjunctions (", and",
", but", ", then").
- Acronym-aware capitalization on merge so MSN/AOL/ICQ stay
all-caps, not "mSN" / "aOL" / "iCQ".
Layer F - injections, LOW-RISK paragraphs ONLY:
- Adverbs mid-sentence (literally, basically, honestly, actually,
really), 20%
- Parentheticals (if memory serves, give or take, close enough,
roughly), 10%
- Discourse markers at sentence start (still, though, anyway,
but yeah, in fairness), 15%
- Fragment interpolations between sentences (anyway., by then.,
either way., for some reason., more or less.), 30%
WHY low-risk only: injecting "casual" markers on already
anchor-poor paragraphs makes them look like humanizer-tool output,
which Pangram is specifically trained against. Anchor-strong
paragraphs tolerate noise; anchor-weak ones get flagged for
attempting it.
Layer G - always applied:
- Swap one random adjacent sentence pair in the middle of the
paragraph, 20%
4. PARAGRAPH-LEVEL VARIANCE
Split paragraphs that have 7+ sentences in half, 30%.
5. REASSEMBLE the body and return.
DETERMINISM
seed = stable_hash(slug + paragraph_index) # zlib.crc32
rng = random.Random(seed)
Every transform that uses random takes this rng.
Same input gives same output, every run, every machine.
THE ASYMMETRY THAT MAKES IT WORK
- Drops apply universally. Removing AI signal is always safe.
- Injections apply to low-risk paragraphs only. Adding "casual"
noise to risky content triggers Pangram's humanizer-tool
detector and makes the score worse.
- Aggressive structural cuts apply to high-risk only. Essay-shape
paragraphs need surgery, not word swap.
- Closing 2nd paragraphs are dropped entirely. No amount of
rewriting saves a pure-essay reflection.